:format(webp))
Anthropic’s release of Claude Opus 4.8 last week is a good moment to notice why model selection needs a new framework: you can no longer pick the latest model and think you’re done. Rather, you have to consider the model landscape to make an informed decision. Opus 4.8 tops independent tests for both writing and coding, which a year ago would have settled the matter. It doesn’t anymore. GPT-5.5 still leads on agentic execution and quantitative accuracy. Gemini offers good price-to-quality. And for a surprising number of everyday jobs, the right model is one of the cheaper ones. The lead has become task-specific.
This isn’t a temporary quirk of the current release cycle. It’s what specialization looks like once a field matures.
The decision that matters, then, is no longer which model is best, but which model fits the job in front of you. In a workspace tied to a single model, that question barely arises - you use what you have. In a model-agnostic one, it becomes a routing decision that admins and users make per task, dozens of times a day, mostly without thinking about it. If you work in a model-agnostic AI workspace - nuwacom or otherwise - this piece guides you through the decision process.
Why “best AI model” stopped being a useful question
The models have stopped converging and started specializing. As of June 2026, each of the leading models now has a recognizable shape: a set of things it does better than the others, and a corresponding set of trade-offs.
Opus 4.8 is precise and conservative. It interprets instructions literally and is markedly more willing to flag its own uncertainty than its predecessors, which makes it trustworthy for high-stakes work and occasionally frustrating for loose, exploratory prompting.
GPT-5.5 has the opposite temperament - it runs ahead, plans, and executes across long multi-step tasks - but independent testing flags a measurable tendency to hallucinate that the others don’t share to the same degree. Haiku and the Gemini models offer good value for money. o3 reasons more deeply than it writes.
There is no longer a one-dimensional ranking. The models are, effectively, all different tools. Creating a single leaderboard to choose among them would be like looking at a car’s top speed to decide whether it’s the right vehicle for a delivery fleet. Today’s go-to move is to understand which model is the best choice for the job at hand.
Which AI model for which task
What follows is a working map of the jobs an organization actually runs through an AI workspace, and the model best shaped for each. The map is opinionated by design - it tells you where to start, not the only place you could land.
Two reading notes before the table. First, “best for the job” includes cost: a model that is marginally better at twice the price is not better for most everyday work. Second, this reflects the June 2026 generation specifically. The jobs are durable; the models will change over time.
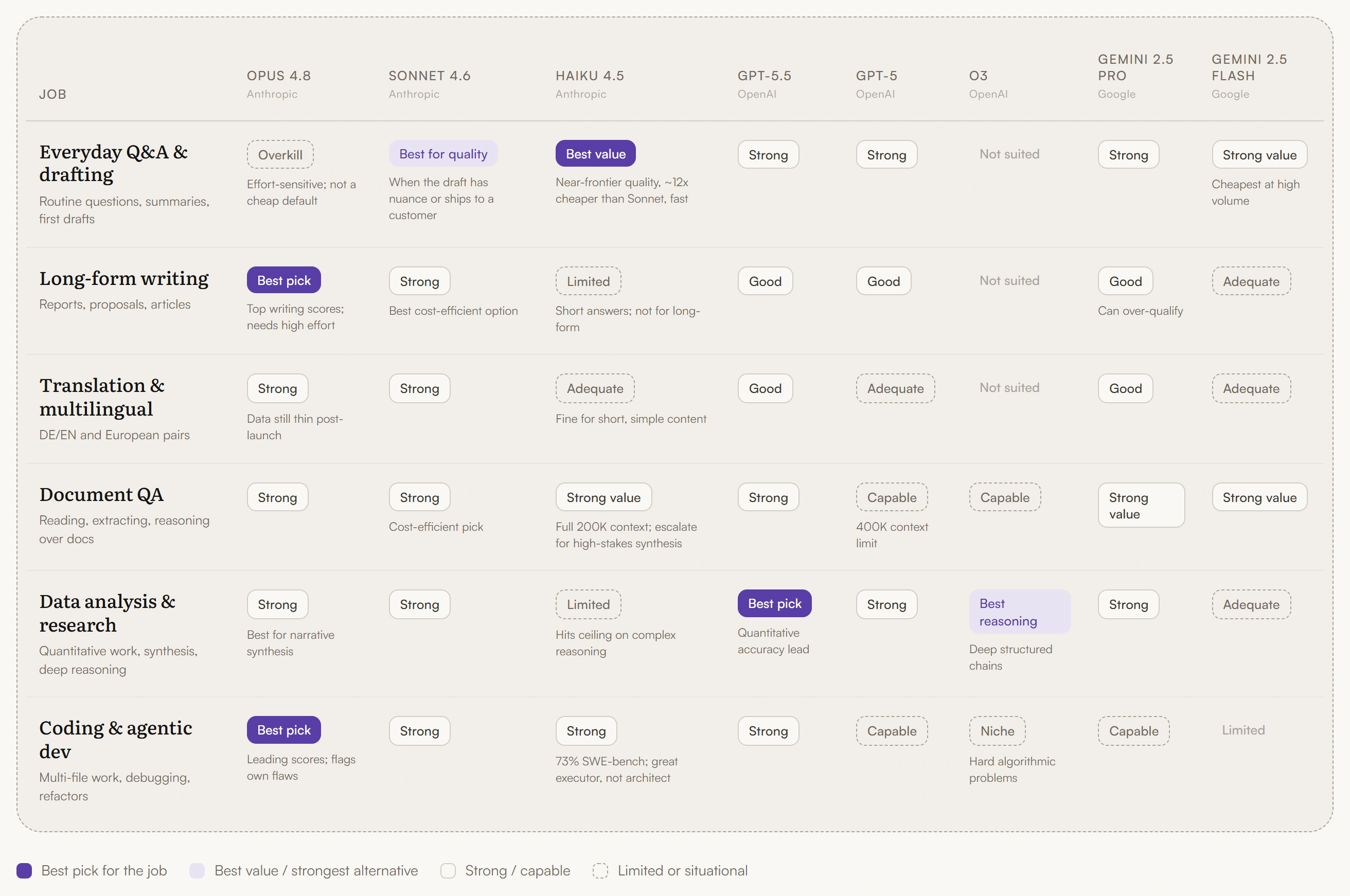
Everyday questions and drafting are the most common jobs, and the ones where reaching for the flagship is most often a mistake. The cheapest capable model usually wins here: Claude Haiku 4.5 handles routine questions, summaries, and first drafts at roughly a twelfth of Sonnet’s per-token cost and noticeably faster, which makes it the natural default for high-volume everyday work. Step up to Claude Sonnet 4.6 when the draft has nuance or is going to a customer - it stays close to Opus quality at a fraction of the price. The flagship’s advantages - deeper reasoning, longer autonomous runs - simply don’t surface in a two-paragraph answer.
Long-form writing is where Opus 4.8 earns the flagship price. Independent writing evaluations place it ahead of the field, with fewer of the tells that mark text as machine-written. The caveat is operational rather than qualitative: that quality is real at higher effort settings and degrades noticeably at lower ones - the effort level being how much reasoning the model is told to spend on a response - so for serious writing, the effort setting is part of the instruction, not an afterthought.
Translation and multilingual content is the job nearly every DACH organization runs daily, and the one where the cost-effective answer is clearest. Independent, human-scored evaluation has consistently placed Mistral’s models in the top tier for European language pairs, German included, and it was built with multilingual fluency as a design premise rather than a capability bolted on afterward.
The honest caveat: prose-translation quality is genuinely pair-dependent - no single model wins every direction. For German-English business content, the practical conclusion holds regardless. You do not need to pay flagship prices to translate well.
Document analysis and synthesis is a field with little to separate the top models in terms of quality, which makes cost and context length the differentiators. Where a model can hold an entire contract or report in a single pass, the cheapest capable option usually wins. Haiku 4.5 is unusually strong for this job - it carries the same 200K-token context as the larger Claude models, so for standard document Q&A the value pick and the quality pick often converge. Reserve a flagship for high-stakes synthesis where an error is expensive.
Data analysis and research are split three ways. For quantitative accuracy and end-to-end task execution, GPT-5.5 leads according to reported GDPval results. For deep, structured reasoning chains - the kind of problem where the logic matters more than the prose - o3 is the specialist. And when the output needs to become a readable, well-argued narrative, Opus 4.8 does the synthesis best.
Coding and agentic development is Opus 4.8’s home territory, where it posts the strongest scores of any generally available model and is substantially less likely than its predecessor to let a flaw in its own code pass without flagging it.
The prompting-style caveat
The matrix above tells you what each model is good at. But there is a caveat that may influence what the best decision is for your team: Opus 4.8, just as its predecessor, interprets prompts literally and explicitly. It does not silently generalize an instruction from one example to the rest, and it does not infer requests you didn’t make.
For carefully written prompts, this is a feature: precision, predictability, less drift. But it means a prompt tuned for a more generous model can under-deliver; for instance it will apply a formatting rule only to the first section and not the rest, because you only mentioned it in the first section. Users who are not well-versed in prompting in this manner will likely get subpar results and would benefit from a more liberal model such as Sonnet 4.6 or the GPT models.
Architecture over models
Notice what every recommendation in this piece quietly assumes: that you can switch. Pick Haiku for the quick draft, Opus for the proposal, Mistral for the German translation, GPT-5.5 for the data run - that entire sequence is a routing decision, and it is only available to you if the model is a parameter you set, not a platform you are locked into.
An organization standardized on a single model doesn’t get to choose the right model per job. It absorbs one model’s weaknesses across every job as a fixed cost - the hallucination tendency in its compliance work, the literalism in its brainstorming, the flagship price on its everyday questions. The durable advantage was never a particular model. It is the architecture around the models - the layer that lets the choice above exist at all. This is the premise nuwacom is built on, and it is why we build model-agnostic by design rather than as a single integration.
How to actually decide
A workable routing logic comes down to a few heuristics:
Default down, escalate on evidence. Start with the cheaper, capable model - Haiku 4.5 or Gemini Flash - and move up only when the output actually falls short. Most everyday work never needs the flagship, and reflexively reaching for it is the most common way teams overspend on AI.
Match effort to stakes, not to habit. Where the effort level is adjustable, treat it as part of the task. A throwaway question doesn’t need maximum reasoning; a board memo does - and on some models, the gap between effort settings is the gap between publishable and generic.
For factual and regulated work, prefer the model that doubts itself. When a wrong answer is expensive - compliance, legal, financial - Opus 4.8’s willingness to flag uncertainty is worth more than a marginal benchmark lead elsewhere. A model that tells you when it isn’t sure is safer than one that is confidently wrong.
For translations, don’t pay flagship prices. Translation and multilingual content is a high-volume task and well-served by cheaper, European-built options. Reserve the expensive models for the work that genuinely needs them.
None of these heuristics leads to permanent answers. That is the point.
The model layer won’t hold still
Opus 4.8 is a week old and already the fifth Opus release in roughly seven months. By the time the next one lands, some of the cells in the table above will have moved. That dynamic is exactly why the answer to “which model should we use?” can’t itself be static. It has to be a way of deciding - a routing logic that survives the next release, and the one after that. Get the logic right, and each new model becomes an upgrade you slot in, not a migration you survive.
We will update this guide as the landscape shifts. The framework underneath it is built to outlast the snapshot.
nuwacom is the model-agnostic AI operating system for European organizations - the layer that lets you route every task to the right model, under your own governance and jurisdiction. nuwacom.com